In a series of posts, I will study the properties of the Multilayer Perceptron (MLP), starting with the capability to learn some mathematical functions (XOR, y=X², ..). This subject has been studied long time ago by researchers and George Cybenko demonstrated that any function could be approximated by a MLP (see Cybenko, G. 1989. Approximation by superpositions of a sigmoidal function). However it’s always interesting to study such a subject to have a clear understanding of the properties of the MLP. Reading one thing is not the same as testing it.
Properties of the Multilayer Perceptron
The main results of this study of the capability of the MLP to learn XOR are:
- More than 1000 data in the training set are needed to get an error below 5% of accuracy
- different topologies of the MLP leads to same results
- adding more than 1 layer improve the results accuracy
- above a certain number of layers or neurons per layer, more training data is needed in order to get an error below 5% without significant gain in the results accuracy
The XOR function
The XOR operator is one of the operators in classical logic among NOT, AND, OR, IMPLY, EQUIVALENT and Its truth table is the following

The MLP
For more information about the Multilayer Perceptron see :
- Basics of Multilayer Perceptron
- Brief Introduction on Multi layer Perceptron
- The Multilayer Perceptron – Theory and Implementation of the Backpropagation Algorithm
For my tests, I chose to use a MLP with the tanh function as the activation function of the neurons in the hidden layers. At the beginning of each training sessions, all the weights of each link from one neuron to the neurons of the next layer were set to a random value. I ran my tests using several topologies:
- 2 3 1 (2 neurons on the entry layer, 3 neurons on the hidden layer, 1 neuron on the output layer)
- 2 4 1
- 2 5 1
- 2 6 1
- 2 8 1
- 2 10 1
- 2 4 4 1 (2 hidden layers with 4 neurons on each layer)
- 2 4 4 4 1 (3 hidden layers with 4 neurons on each layer)
- 2 4 4 4 4 1
- 2 4 4 4 4 4 1
The training data set was built using random entries among the 4 possible entries (0 0 ; 0 1; 1 0 ; 1 1). A series of 4000 entries were created for the training data set. At each step of the training process we measure the difference between the calculated output and the desired result and compute an average on 30 entries.
Results of the tests
A picture being worth a 1000 words, let’s see the results for a single hidden layer
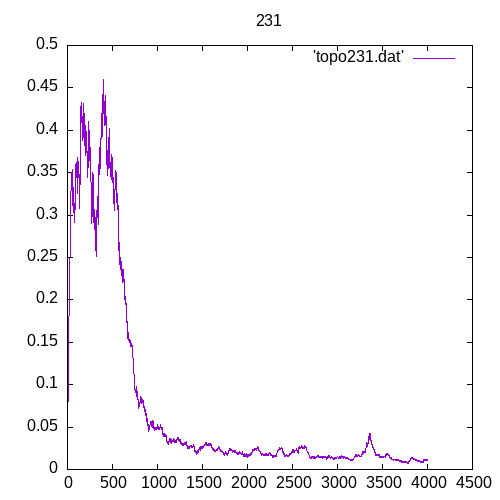
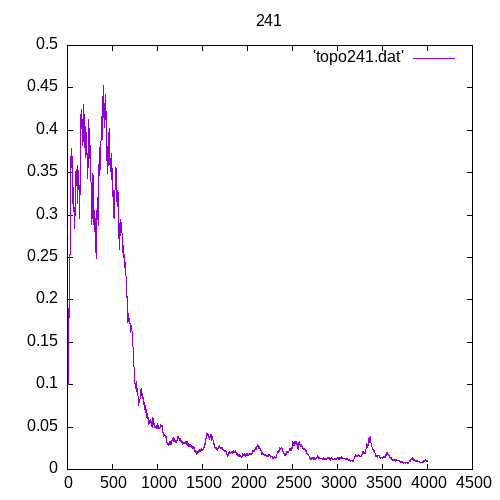
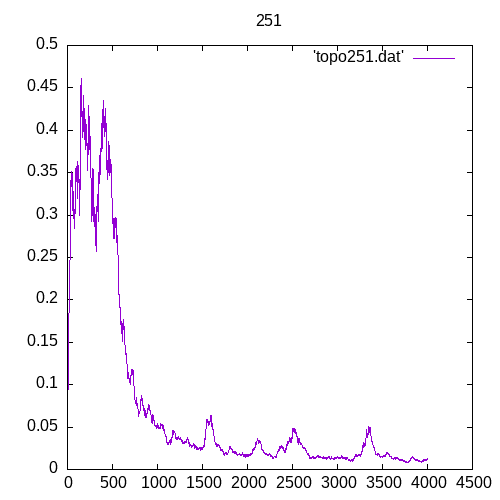
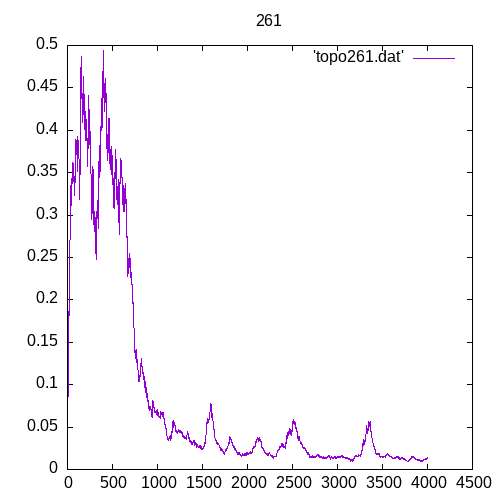
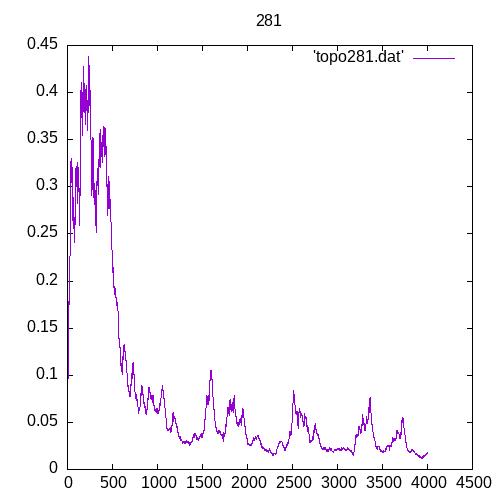
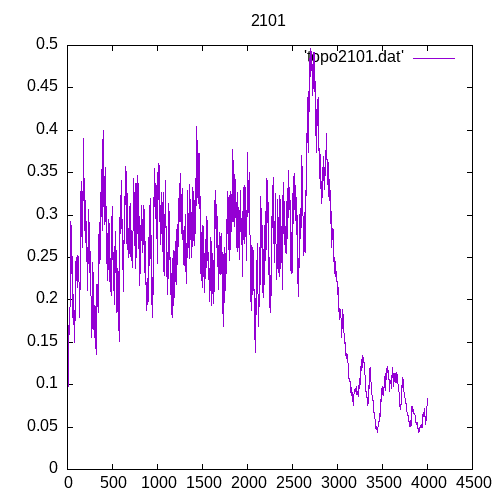
Now let’s see the results for several hidden layers
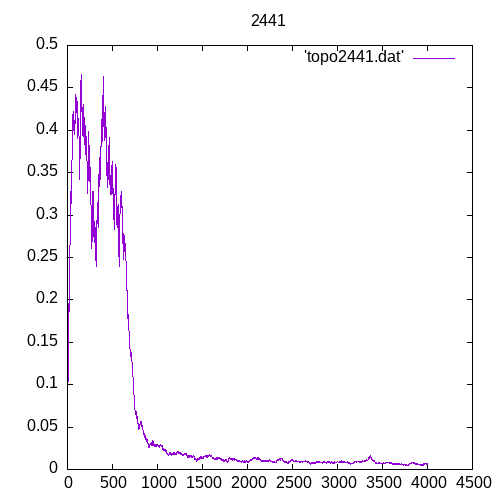
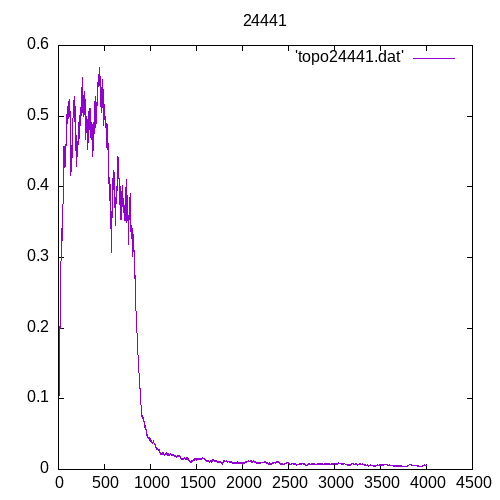
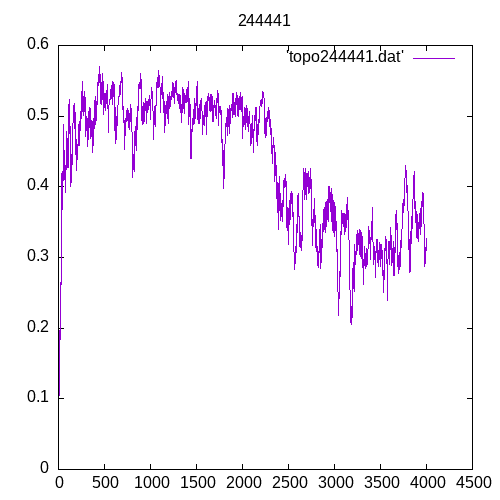
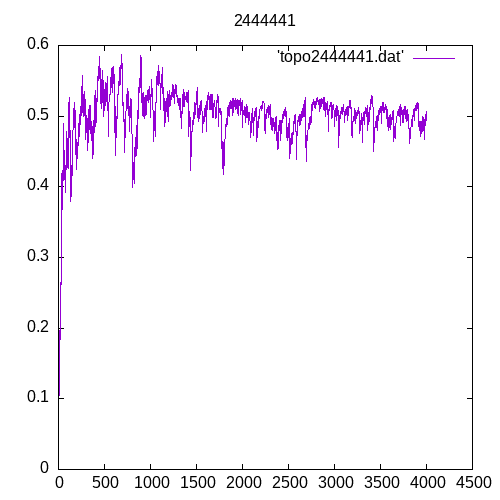
Once again at 4 or above hidden layers the number of entries of the training set must increase significantly to train the MLP
Another interesting image to look at is the result of the MLP output function for values other than 0 or 1. Below we can see the output function of the MLP for parameters of the XOR operator in the range -1 to 2 for a MLP topology of 2 4 4 1

Virtually all of what you point out is astonishingly accurate and it makes me ponder the reason why I had not looked at this with this light before. Your article truly did turn the light on for me personally as far as this subject goes. Nevertheless at this time there is one issue I am not too cozy with and whilst I try to reconcile that with the actual central idea of your point, permit me see just what the rest of the subscribers have to point out.Well done.