This article is about the capability of the MLP to learn incrementally in the same way as the brain does. The main result of this article is that MLP does not learn incrementally because it forgets what has been learned using the preceding training sets.
Incremental Learning
When we (as human beings) learn something (for example the function XOR), we don’t start from nowhere. We already have some knowledge of prior information and we use this prior information to reduce the number of things to learn. For example when we learn the function XOR, we already know what a function is, we already know what are the main operators of classical logic (AND, OR, NOT, IMPLY, EQUIVALENT). We use some of what we already know to reduce the amount of information to learn and the time needed to learn. Does the MLP exhibit such a property ?
For an overview of the properties of the MLP, see my previous posts:
- Capability of the MLP to learn
- Gradient Descent Algorithm: Impact of eta and alpha on the learning curve of MLP for XOR
- Gradient Descent Algorithm: Impact of topologies on the learning curve of MLP for XOR
For an introduction to incremental learning, see:
- Learning Deep Neural Networks incrementally forever
- Incremental learning algorithms and applications
The tests
Since neurons compute the output from parameters which are real numbers, information like AND, OR, NOT, XOR can not be processed directly. AND , OR, NOT, XOR functions were converted using the following rule: AND = 0 OR = 0.25 NOT = 0.5 XOR = 0.75.
A final training set was created by aggregating 4 different training sets, one for each logical function. Each training set for a logical function was created with 4000 random entries, each entry using 3 parameters: the logical function, the first operand, the 2nd operand.
See below for an example of an entry of the training set for the OR function
in: 0.25 1.0 0.0
out: 1.0
2 tests were created: the first one with a final training set having the following order AND, OR,NOT,XOR and the second one with a final training set having the following order AND,OR,XOR,NOT.
The 2 final training sets had 16000 entries and were composed of 4 training sets (one for each logical function) having 4000 entries each. I tested the 2 final training sets with several topologies and the results were the same whatever the topology.
Results of the tests
A picture being worth a 1000 words, let’s see the learning curve for a 3441 topology and the first training set (AND, OR,NOT,XOR).
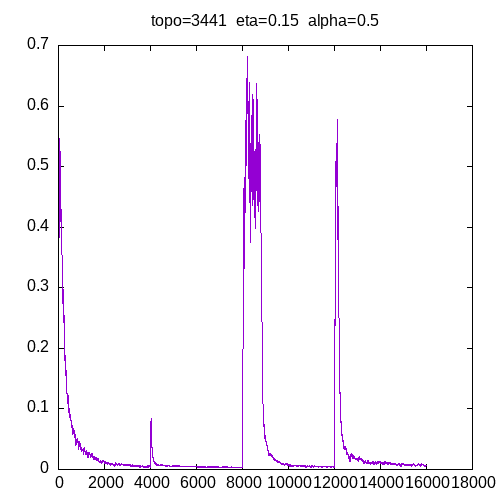
As we can see, each change of the logical function training set generates a big increase in the error between the calculated output and the expected output. Then the learning process occurs and the error between the calculated output and the expected output decreases.
However if we look at the result of the learning:
| Logical function | 1rst operand | 2nd operand | Output |
|---|---|---|---|
| AND | 0 | 0 | -0.232148 |
| AND | 0 | 1 | 0.966412 |
| AND | 1 | 0 | 0.915875 |
| AND | 1 | 1 | 0.190818 |
| OR | 0 | 0 | -0.174888 |
| OR | 0 | 1 | 0.981836 |
| OR | 1 | 0 | 0.968957 |
| OR | 1 | 1 | 0.109686 |
| NOT | 0 | 0 | -0.0969815 |
| NOT | 0 | 1 | 0.987154 |
| NOT | 1 | 0 | 0.982831 |
| NOT | 1 | 1 | 0.0477247 |
| XOR | 0 | 0 | 0.000263177 |
| XOR | 0 | 1 | 0.988387 |
| XOR | 1 | 0 | 0.985898 |
| XOR | 1 | 1 | 0.000674487 |
All the logical operators have nearly the same outputs corresponding to the XOR operator.
Now let’s see the learning curve for a 3441 topology and the second training set (AND,OR,XOR,NOT).
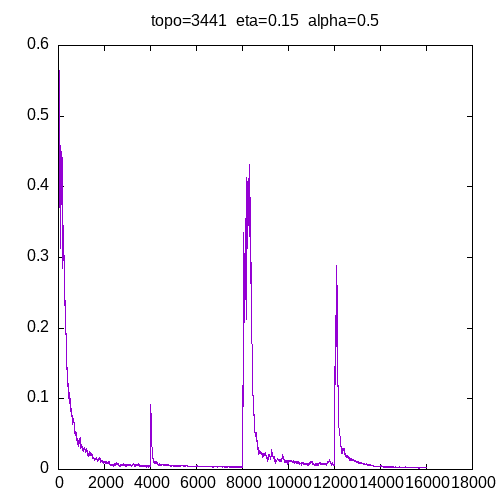
Now let’s see the result of the learning
| Logical function | 1rst operand | 2nd operand | Output |
|---|---|---|---|
| AND | 0 | 0 | 0.974839 |
| AND | 0 | 1 | 0.998576 |
| AND | 1 | 0 | 0.0626129 |
| AND | 1 | 1 | 0.00455376 |
| OR | 0 | 0 | 0.988773 |
| OR | 0 | 1 | 0.998039 |
| OR | 1 | 0 | 0.0213727 |
| OR | 1 | 1 | 0.00192115 |
| XOR | 0 | 0 | 0.997523 |
| XOR | 0 | 1 | 0.985631 |
| XOR | 1 | 0 | -0.0090343 |
| XOR | 1 | 1 | -0.000548065 |
| NOT | 0 | 0 | 0.995078 |
| NOT | 0 | 1 | 0.995744 |
| NOT | 1 | 0 | 0.000851807 |
| NOT | 1 | 1 | 0.000360301 |
All the logical operators have nearly the same outputs corresponding to the NOT operator.
This clearly demonstrates the process of forgetting the preceding information after a new set of training.